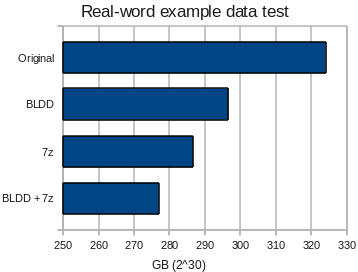
Evaluating space savings using my media library as test data. Mixed text, images, audio and video.
The BLDD program is a compression utility, in a sense. It would be more accurate to refer to it as a block-level offline deuplication utility, but it functions in exactly the same manner as a true compression utility: A file goes in, a (hopefully) smaller file comes out. An extraction utility can reverse the process.
Block-level de-duplication is commonly used transparently when storing very large amounts of data, either as part of the filesystem or block device. It is a simple concept: Consider each file as a series of blocks (usually fixed-size for convenience), and store each unique block only once. All subsequent appearances of the block may be replaced with pointers.
BLDD uses block-level deduplication, not as part of a filesystem, but within a single file. For most files, this would be of no benefit. There are though certain niches, types of file for which duplicated but widely separated blocks are normal - most importantly drive images, virtual machines and tar files containing duplicated files or parts of files within.
Used alone, BLDD is a not-particually-good compression utility. It is designed to function together with a conventional compression program. As it works in a manner quite unlike any other in common use, and passes unique blocks through unaltered, the reduction when combined with conventional compression is cumulative. A hard drive image processed with BLDD will compact well, as will the image processed with a utility such as 7zip - but an image processed with BLDD and then 7zip will compact better than either utility can achieve alone.
BLDD is intended for use in archival or backup applications, where speed of access to the data is not a great concern but high compression and thus reduced cost of storage is highly desireable. Deduplication/compression is a highly time-intensive process, and random access to the contents of a deduplicated file is not possible without extracting fully.
Algorithm description
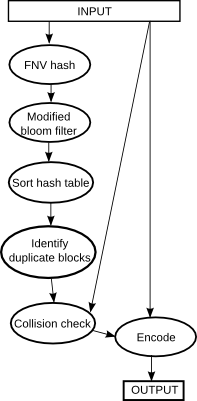
1. Input data is hashed in fixed-width blocks (default 512 byte). To improve performance, all-zero blocks are skipped. The list of hashes is written to a temporary file, as it may be too large to hold in RAM or within the 4GB address space of a 32-bit process. The hash used is a 64-bit non-cryptographic FNV hash. Collisions (Chance or induced) are a possibility at this stage.
2. In order to identify duplicate blocks, this list is filtered by a modified bloom filter, in which each cell has three possible states (Not seen, seen once, seen more than once). This is able to eliminate almost all of the non-duplicated blocks from consideration early on in the de-duplication process, and so reduce the block-hash table to a more manageable size, though as with any bloom filter it can only reject blocks with confidence - non-duplicate blocks may still pass. The tristate bloom filter is functionally identical to the two-filter design developed independantly by Meyer and Bolosky for their own deduplication studies. They differ only in the layout of the table in memory.
3. In order to eliminate all non-duplicated hashes with certainty, the list must be sorted by hash. This is done using a radix sort. For random-valued data, the radix sort is little different to quicksort. An advantage of this sort algorithm is the serial nature of access, which is of great performance benefit when data cannot fit in RAM. When partition size grows small enough, an in-memory implementation is used. A stable sort is required, or else the sort must be extened to preserve block number ordering. The radix sort is stable.
4. All non-duplicated blocks are eliminated.
5. The list is re-sorted by block number. For simplicity, the same sort algorithm is used, the block numbers having been converte to big-endian format first. While a faster algorithm may be possible implementation would be complicated by the need to use serial access only.
6. The list is refined from <hash><block number> pairs into <block number><earlier block location> pairs. The first occurance of each block is discarded.
7. Each block pair is verified by comparison within the original file. This is to guard against hash collisions.
8. Finally, this block pairing list is used in conjunction with the original file to produce the de-duplicated output file.
The format used for BLDD has theoretical worst-case performance giving an increase in file size of 0.19% on input specifically crafted to be ill-suited to the software, or a more typical worst-case of a 0.00076% increase when the input is random.
In practical testing, BLDD has demonstrated the ability to improve upon 7zip alone by 3% even when using data in which few block duplicates might be expected. The test file used was a tar representative of a typical data set that might be encountered when making backups (My vast collection of funny internet pictures, classic Doctor Who episodes, useful utilities and drivers). 7zip was used with the -md=256m option, the largest dictionary size practical.
Although development continues on the encoder, the BLDD format is finalised. The program is currently functional, and available, but unpolished. The latest version is 1.5.
When making backups of drive images, it is advisible to zero out unallocated space to improve compressibility.
Version 1.1: Added support for block sizes other than 512 bytes. The expansion program compiles under Windows (Visual Studio), but compaction was limited to *nix.
Version 1.5: Substantial improvements in performance - more than a doubling of speed. This is achieved by adding a check to guard against hash collisions, which in turn allows moving from 128-bit hashes to 64-bit, a size much more manageable. The MD5 hash is also replaced with the less CPU-intensive FNV non-cryptographic hash. A revised makefile includes self-test procedures and the ability to cross-compile the extraction program for Windows using mingw. Cross-compiling of the de-duplicator itsself is still untested. This version is currently undergoing final testing.
Version 1.7: Rewrote the sort algorithm as recursive. Substantially faster. Stripped all remaining MD5 code from BLDDCompact - it's purely FNV-64 based now. Added more validity checks - if the sort does go wrong (should never happen), there's a good chance these will detect the inconsistancy rather than continue and corrupt data.